これは SRE Advent Calendar 17日目の記事です。
2022年に引き続きSRE Advent Calendarをやっていきます。
※今回は一部ChatGPTを使って文章生成しています。
背景
データベースのデータ量が日々増大していく中で、その監視は非常に重要な課題となっていました。特に、Amazon Aurora(以降Aurora)のようなストレージを気にする必要がない*1マネジメントサービスが普及する現代において、データ量の増加を見逃してしまうリスクが高まっています。
確かにAurora クラスターボリュームは信じられないほどのデータ量をサポートしているように見えますが、それは全体サイズであってテーブルサイズではないことが、今回は重要です。
テーブルごとのデータサイズが過度に増加すると、マイグレーションやその他のメンテナンス作業で問題が生じてきます。これを事前に防ぐためにも私たちは、数年後にはシャーディングを検討することになるでしょう。その前に、データサイズの増加を正確に把握し続けることが不可欠でした。
それまで本番環境に入り込み手動でinformation_schemaから情報とって集計していましたが、ようやく自動化に時間を当てたというわけです。
環境
私たちは、この課題に対処するために次のものを採用しました。
- Datadog
- Prometheus Exporter
- Kubernetes
この選択の背後にはいくつかの重要な理由があります。まず、Datadogは私たちの会社で広く利用されており、その強力なモニタリング機能を活用することができます。
次に、Kubernetesは私たちのサービス基盤として中心的な役割を果たしています。
最後に、mysqld_exporterはinformation_schemaの集計をサポートしており、これによってMySQLのデータサイズを効率的に収集し、Datadogに送信することが可能になります。
概要
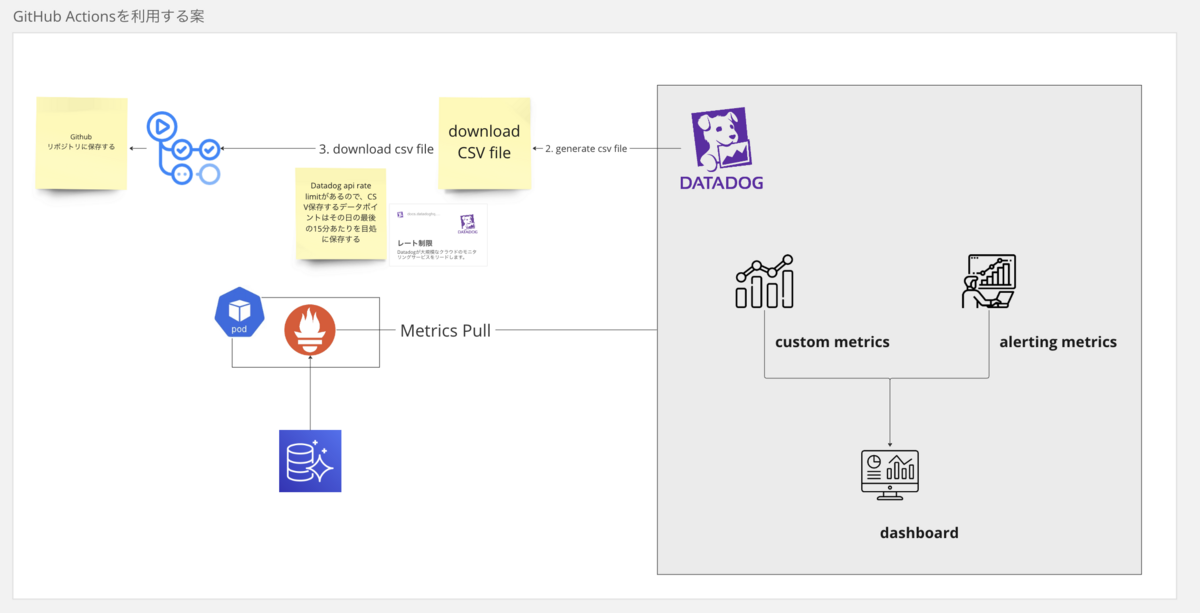
大まかな監視構成は以下のようなものです。なお本記事ではCSVダウンロードやGithub Actionsの部分には触れませんが参考として記載しておきます。
- mysqld_exporter v1.14.0
- csv_download → Datadog公式のライブラリ(GitHub - DataDog/csv_exporter)をForkして自分たちように修正
- Github ActionsでCSVダウンロードを定期的に実行し、正確な数字をCSVとして保存しておく
※mysqld_exporterバージョンの最新はv.1.15.0ですが、環境変数の取り扱いで意図した挙動にならなかったためv1.14.0を使用しています*2。
Manifest
mysqld_exporterのREADMEにはDockerでの使用方法しか書いてません。したがって、KubernetesのManifestで意図通りに動かす工夫が必要です。
apiVersion: apps/v1 kind: StatefulSet metadata: name: mysqld-exporter spec: serviceName: xxx-mysqld-exporter podManagementPolicy: OrderedReady updateStrategy: type: RollingUpdate replicas: 1 selector: matchLabels: app.kubernetes.io/name: mysqld-exporter template: metadata: labels: app.kubernetes.io/name: mysqld-exporter annotations: # https://docs.datadoghq.com/ja/developers/write_agent_check/?tab=agentv6v7 # https://github.com/DataDog/integrations-core/blob/6d0bf89095012307b4fa0bf2cb927fb9eb7c2a9f/kube_apiserver_metrics/datadog_checks/kube_apiserver_metrics/data/conf.yaml.example#L521 ad.datadoghq.com/mysqld-exporter.checks: | { "openmetrics": { "init_config": {}, # 空だが記述する必要がある "instances": [ { "openmetrics_endpoint": "http://%%host%%:9104/metrics", "namespace": "mysql", "metrics": [ {"mysql_info_schema_table_rows": "info_schema.table_rows"}, {"mysql_info_schema_table_size": "info_schema.table_size"} ], "min_collection_interval": 86400 # 一日に一度だけクエリを実行するように設定 } ] } } spec: containers: - name: mysqld-exporter # 不要な情報はコレクトしないようにする args: - --collect.info_schema.tables - --no-collect.global_status - --no-collect.global_variables - --no-collect.slave_status - --no-collect.info_schema.innodb_cmp - --no-collect.info_schema.innodb_cmpmem image: prom/mysqld-exporter:v0.14.0 imagePullPolicy: Always # 省略(resources, vaultなど) . . .
- 基本的にはDatadogとmysqld_exporterのドキュメントを参考しながら書き上げました。DockerとKubernetesでflagsの渡し方が異なるあたりは注意が必要でしょう(docker-composeで検証したときとcommandとargsの挙動が違ったので利用する人は気をつけたい)
- この部分でどのようなメトリクスとして送るか設定できます
ad.datadoghq.com/mysqld-exporter.checks: | { "openmetrics": { "init_config": {}, # 空だが記述する必要がある "instances": [ { "openmetrics_endpoint": "http://%%host%%:9104/metrics", "namespace": "mysql", "metrics": [ {"mysql_info_schema_table_rows": "info_schema.table_rows"}, {"mysql_info_schema_table_size": "info_schema.table_size"} ], "min_collection_interval": 86400 # 一日に一度だけクエリを実行するように設定 } ] } }
mysqld_exporterがinformation_schemanに対してリクエストする間隔を一日おきにしています。これはmin_collection_intervalを指定することで可能です
また、{"mysql_info_schema_table_size": "info_schema.table_size"} は、mysql_info_schema_table_size という名前でmysqld_exporterがoutputするので、それをinfo_schema.table_sizeというメトリクス名としてマッピングするようにしています。したがって、Datadogには"namespace": "mysql"の部分と合わせてmysql.info_schema.table_sizeという形で登録されます(カスタムメトリクスなので課金対象です)。
データベース側での設定
MySQLに対してユーザ作成と適切なGRANTをする必要があります。
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'XXXXXXXX' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
しかし、ややGRANTが過剰です。私が今回取得したいのはinformation_schema情報だけなので、BINARY LOGS が読める必要はないのでREPLICATION CLIENTは消しました。
GRANT PROCESS, SELECT ON *.* TO 'exporter'@'localhost';
すべてのテーブルに対して権限は必要なのだろうか?と思ったのですが、information_schemaは対象のテーブルの権限を持っていないと表示しないようなのでこの内容でよさそうです。
For most INFORMATION_SCHEMA tables, each MySQL user has the right to access them, but can see only the rows in the tables that correspond to objects for which the user has the proper access privileges. In some cases (for example, the ROUTINE_DEFINITION column in the INFORMATION_SCHEMA ROUTINES table), users who have insufficient privileges see NULL. Some tables have different privilege requirements; for these, the requirements are mentioned in the applicable table descriptions. For example, InnoDB tables (tables with names that begin with INNODB_) require the PROCESS privilege.
Datadogダッシュボードでみる
Kubernetesで無事動けば、メトリクスが取得されるのでこのようにダッシュボードで加工できます。これはチームメンバーががっつり作り込んでくれました。ちゃんと使われてて嬉しい限りです。

これでいちいち本番環境を見に行く必要がなくなりました。毎週実施している犬を愛でる会(Datadog 定期観測会)でも使用可能です。
おわりに
マネジメントサービス恩恵でストレージサイズを気にしなくて良くなっても、規模が大きくなればテーブルのキャパシティについて考慮する必要があるでしょう。今後はDatadogからCSVダウンロードして保存し、より詳細な数字で分析できるような構成を作ろうとしています(Datadogは期間が大きくなると数字を丸めるので、正確な数字での分析はCSVになると思われる)。
その話はまた別の機会に。
※ChatGPTを使って文章を作らせたのは本の序文までで、結局ほとんど自分で書いてました。ずっと書いてきた自分の書き味と違いすぎて気持ち悪くなったんでしょうか……。
*1:AWS公式によると128TiBのサイズをサポートしている Amazon Aurora ストレージと信頼性 - Amazon Aurora
*2:issueを作成すべきとは思う。アップデートするときにやりたい